阿里技術實戰 揭秘數十萬云服務器的高效運維與數字內容制作服務
在當今數字經濟時代,云計算已成為支撐海量業務與創新服務的基石。阿里巴巴作為全球領先的科技企業,其背后是數十萬臺云服務器構成的龐大集群,如何對這些服務器進行高效運維,并在此基礎上提供穩定、靈活的數字內容制作服務,是一項極具挑戰的技術實踐。本文將深入探討阿里在這一領域的關鍵技術與實戰經驗。
一、規模化運維的挑戰與架構設計
管理數十萬臺云服務器,首要解決的是規模化帶來的復雜性問題。傳統的運維模式在如此龐大的集群面前幾乎失效。阿里通過以下核心架構實現高效運維:
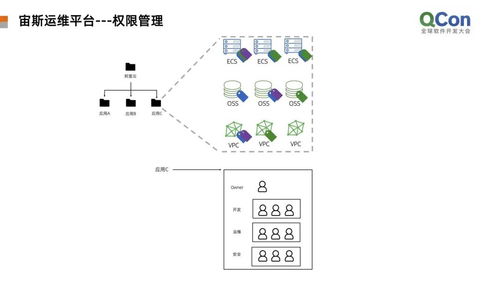
- 統一的資源調度與管理平臺:阿里自研的飛天操作系統是核心調度引擎。它將遍布全球的數據中心數百萬臺服務器連接成一臺超級計算機,實現計算、存儲、網絡資源的統一管理與彈性分配。運維團隊通過一個控制面即可監控全局資源狀態,進行自動化部署與擴縮容。
- 智能化的運維中臺:基于大數據和AI技術,構建了智能運維平臺。該平臺能夠實時采集服務器性能指標、日志和鏈路追蹤數據,利用機器學習算法進行異常檢測、故障預測與根因分析。例如,通過對歷史故障模式的學習,系統可以提前預警硬盤故障或網絡擁塞,實現從“被動救火”到“主動預防”的轉變。
- 不可變基礎設施與容器化:廣泛采用容器技術(如阿里內部的PouchContainer及與社區協同的Kubernetes),將應用及其依賴環境打包成標準鏡像。服務器本身被視為可隨時替換的“牲畜”而非“寵物”。通過鏡像發布,確保環境一致性,結合高效的編排系統,實現秒級的應用部署與跨機房遷移,極大提升了運維效率和系統可靠性。
二、高效運維的核心技術實踐
- 自動化與無人值守運維:建立了覆蓋資源交付、配置管理、監控告警、故障自愈的完整自動化流水線。例如,新服務器上架后,可通過自動化腳本完成固件升級、系統安裝、網絡配置并接入集群,無需人工干預。日常的補丁更新、安全加固也通過“金絲雀發布”等策略自動滾動完成。
- 混沌工程與韌性建設:主動引入故障的“混沌工程”是保障系統穩定性的關鍵實踐。阿里定期在線上環境中模擬服務器宕機、網絡延遲、依賴服務失敗等場景,驗證系統的容錯能力和應急預案的有效性,持續提升集群的整體韌性。
- 精細化成本治理:面對海量資源,成本控制至關重要。通過資源畫像、利用率分析與智能預測,實現資源的超賣與混部。例如,將在線業務(對延遲敏感)和離線計算任務(如大數據分析、視頻轉碼)在同一個集群內混合部署,利用其不同的峰值時段,提升整體資源利用率,顯著降低成本。
三、賦能數字內容制作服務
高效的云基礎設施為上層業務提供了強大動力。在數字內容制作領域,阿里云提供了從內容生產、處理到分發的全鏈路服務:
- 彈性渲染農場:影視特效、動畫渲染需要海量計算資源,且需求波動大。基于阿里云強大的彈性計算能力(如ECS彈性裸金屬服務器、GPU實例),可以快速構建起云端渲染農場。制作方只需按需購買算力,在項目高峰期可瞬間擴展至上萬核規模,項目結束后立即釋放,避免了自建機房的高昂固定投入和資源閑置。
- 智能媒體處理:集成AI能力的媒體處理服務(如視頻點播VOD),能夠對上傳的視頻進行自動化的轉碼、壓縮、截圖、水印添加。更重要的是,利用視覺AI進行內容理解(如智能剪輯、標簽提取、違規內容識別)和增強(如畫質修復、超分辨率),極大提升了內容制作與審核的效率。
- 全球分發與協同制作:利用阿里云全球加速網絡和內容分發網絡(CDN),保障原始素材、渲染中間件、成片在全球團隊間的高速同步與安全傳輸。支持多地藝術家在線協同創作,實現真正的云上數字內容生產線。
四、與展望
阿里通過構建統一、智能、自動化的云基礎設施運維體系,不僅成功駕馭了數十萬臺服務器的復雜性,更將這種強大的計算能力轉化為可被各行各業便捷使用的云服務。在數字內容制作這個典型的高算力需求場景下,云服務器的高效運維直接轉化為了服務的彈性、成本優勢與創新能力。隨著算力進一步池化、AI與運維更深度結合,以及云邊端協同架構的成熟,這種規模化運維的能力將繼續深化,為更廣泛的數字創意產業提供堅實的技術底座。
阿里云的實踐表明,超大規模基礎設施的運維已從一門“手藝”進化為一套數據驅動的“智能工程體系”,這正是其能夠持續穩定地支撐包括數字內容在內的千行百業數字化轉型的核心競爭力所在。
如若轉載,請注明出處:http://www.wnsr027com.cn/product/27.html
更新時間:2026-01-15 22:42:47